INTRODUCTION
Rule-based grammar checking is often inaccurate and takes significant manual effort due to the nuances of natural language. Nevertheless, these systems are desirable for their speed, ability to provide feedback, and the ability to be developed by a linguist with no programming experience.
We leverage dependency parsing to make rule-based systems more accurate, less manual, and resilient to edge cases without sacrificing any of the benefits. With dependency parsing, we can target a specific kind of relation, analyze just two words, and handle many edge cases such as modifiers separating a subject and verb.
This library is written entirely in Python, and provides the necessary tools to create a rule-based grammar checker that uses dependency parsing. It comes with preprocessing scripts that enables you to work with either constituency or dependency parse data, and an efficient CoNLL-U corpus augmentor to improve domain-specific accuracy.
We provide a pre-packaged CPU-optimized English model with a complete rule set, rivaling the accuracy of transformer-based models while remaining extremely small and efficient.
Main developers: Sean Kim, Isaac Nguyen, and Pranshu Sarin
API
Source code for the English API can be found here
To use our API, you can send a POST request to https://api.grammacy.com/predict
with the following JSON body:
"input": "Lorem ipsum dolor sit amet, consectetur adipiscing
elit."
Above POST request will return the following JSON
{ "result":
{ "grammar_errors":
"errors": [
{
"error": error_message,
"corrected_word_index": corrected_word_index,
"suggestion": suggestion
}, ...
]
},
{ "spelling_errors":
"errors": [
{
original_word: suggested_word
}, ...
]
}
}
Note that we enforce a 512 character limit on input text and 2 requests/second per IP address due to cost concerns. If you would like to support us, contact Sean Kim through any of the contacts on his website .
ARCHITECTURE
The library allows you to build your rules in any way you like, but we recommend using a similar architecture to the one used in the pre-packaged English model.
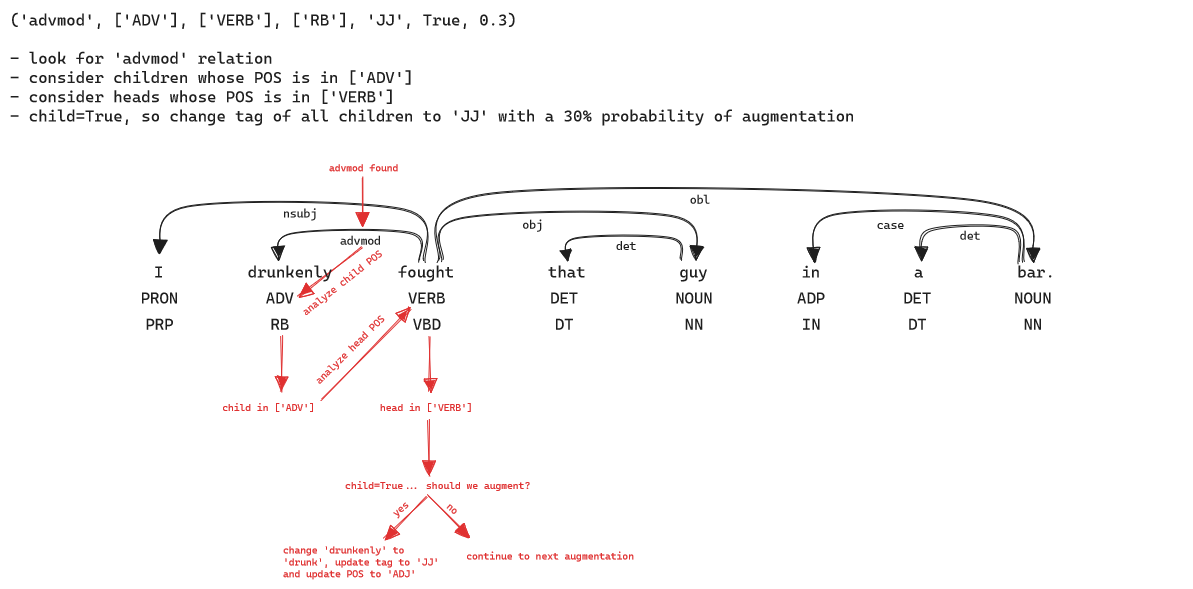
The most important part of building a dependency parser-based grammar checker is ensuring your NLP pipeline can correctly handle both grammatical and ungrammatical sentences. Most available corpora only contain grammatical sentences, leading to situations where the parser, tagger, and other components will attempt to interpret incorrect sentences as if they were correct. To address this issue, we provide a tool that can augment a CoNLL-U corpus with grammar errors that you define. This is a significant improvement upon random error injection, as it enables the incorporation of errors based on actual linguistic knowledge. A diagram explaining the augmentor architecture is provided below, which is an actual augmentation we had to introduce to the English model.
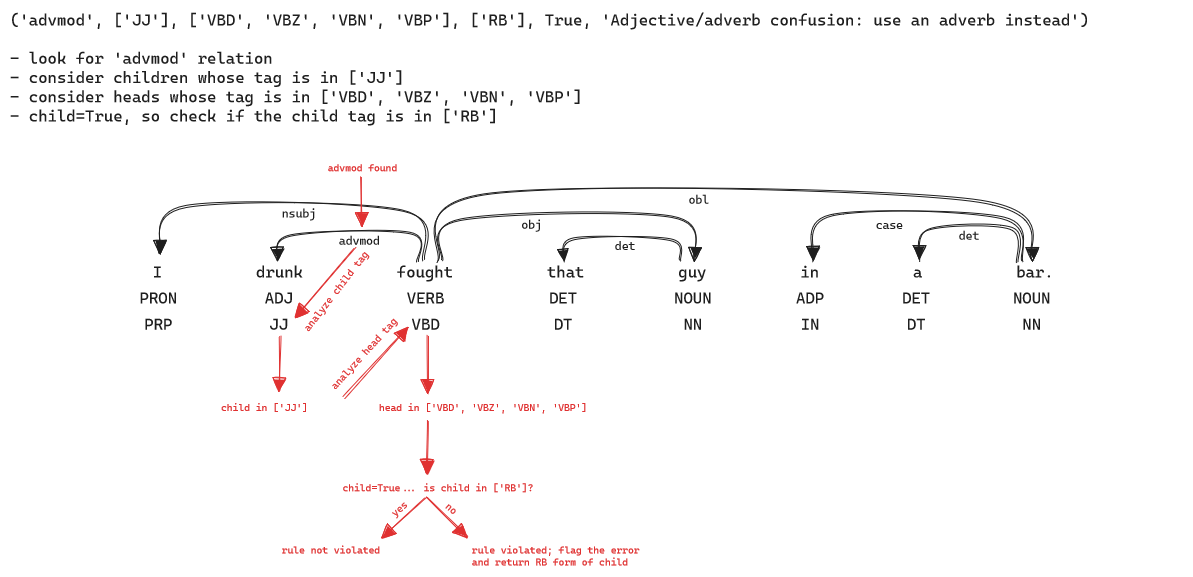
The rule system used in the pre-packaged English model uses a whitelist system, identifying a set of tags that are allowed on each end of a dependency relation. Note that some rules are not as simple as this, and required specific functions to be written. Furthermore, we used the morphologizer for rules that could be improved with it, such as subject-verb agreement.
USAGE
To use this library for your own language and rule set, you will need to follow these steps:
- Download a corpus in PTB or CoNLL-U format. If the corpus is in
PTB, use
preprocessing/constituency2dependency.pyto convert your corpus to CoNLL-U, since the augmentor and spaCy require CoNLL-U format. - Develop your rules. We recommend using the same structure to the one used in the pre-packaged English model to ensure you can easily use the augmentor, but you can use any structure you like.
- Use
preprocessing/conllu_augmentor.pyto inject your errors. It's important to ensure that the errors you inject are based on actual linguistic knowledge to improve domain-specific accuracy. Note that the augmentor is designed to inject very specific errors, so it may become tedious. The errors to inject can be given as a list of tuples, where each tuple contains... - The dependency relation to look for
- The list of child POS to look for
- The list of head POS to look for
- The list of target tags to augment
- A boolean indicating whether the list of target tags applies to the child or head
- A single tag to change all target tags to
- (Optional) The new morphological features
- The probability of the rule being applied
- Train a spaCy pipeline on your augmented corpus. You must train Tok2Vec, DependencyParser, and Tagger components. Optionally, you can train the Morphologizer component if you have rules that can be improved with it. For more information on training, refer to the spaCy documentation.
- You are done! Revise rules, retrain the model, and augment the corpus as necessary to improve accuracy. You can use this model and your rules in your own applications, as we have done here.
TIPS
To create an effective model, we recommend following these tips:
- Use proven corpora such as OntoNotes 5.0 or GUM.
- Inject errors based on actual linguistic knowledge. This will improve domain-specific accuracy.
- Use a similar configuration to the pre-packaged English model, ensuring small yet accurate models.
- Train your own Tok2Vec component. Pretrained vectors usually only contain grammatical sentences.